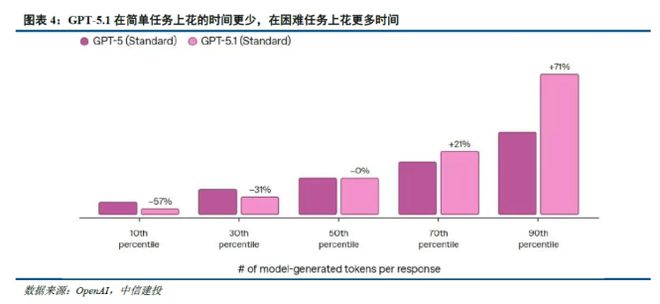
智通财经APP获悉,中信证券发布研究报告称,海外GPT-5.1的更新重点是效率升级和个性化,国内车型也在加快迭代。百度(09888)问心5.0拥有突出的多模态理解能力,有望为模型后续迭代提供更丰富的数据语料。 Minimax M2和Kimi K2的思想先后位居开源模型榜首。前者是专门为代理和代码设计的,成本仅为Claude 3.5 Sonnet的8%;后者将在代币效率、情感表达等工程模型方向不断迭代,优化模型性能。未来,依靠国内的工程优势以及大公司和用户的使用反馈,国产模型和AI应用产品具备追赶国外的基础。中信集团建设要点具体内容如下: GPT-5.1更新,重点是效率升级和个性化。 2025年11月13日,OpenAi发布了GPT-5.1,包括GPT-5.1 Instant和GPT-5.1 mental版本。据Openai官方公告,Instant比前任“更勤奋、更聪明、更善于遵循用户指令”,同时思维“更容易理解、更快地处理简单任务、处理复杂任务”。同时,Openai进一步升级了GPT的路由能力,使其能够根据问题的复杂程度精确调整思考时间。此外,OpenAI还进一步优化了GPT风格功能的设置。目前,除了默认设置外,还支持专业、友好、休闲、怪异、伟大、讽刺、书呆子等不同风格。与之前的 OpenAi 模型更新相比,GPT-5.1 更注重改善用户偏好(命令跟随、高效路由和样式预设)),这意味着OpenAI也开始关注工程模型。目前的全局头部模型能力基本可以满足大多数一般情况的需求。通过工程提高效率和体验已成为制造商的当务之急。国产车型加速突破,能力更加接轨国际前沿。近期,国内模式重复加速,开源模式的头把交椅多次易手,这进一步体现了国内AI领域逐渐向国外边境靠拢。未来,依托国内的工程优势和庞大的用户群体的使用反馈,国产模型和AI应用产品具备追赶国外的基础。百度:11月13日,2025百度世界大会上发布问信5.0。采用原生全模态统一建模,支持文本、图像联合输入输出、音频、视频等信息,实现原生全模态统一理解和生成。从总参数规模来看,文信5.0达到2.4万亿的系列新高,位列发布行业模型第一。主动参数比例小于3%,在保持模型强大能力的同时,有效提升了识别效率。能力方面,文心5.0在多模态理解、指令合规、创意写作、现实、智能体规划、工具应用等方面均具有较强的能力,各方面表现出色,具有较强的理解力、逻辑性、记忆力和说服力。在40多个编写的基准测试综合分析中,语言理解和多模态能力与Gemini-7.5-Pro、GPT-5-high等模型一致,图像和视频生成能力相当于现场领域专用模型,达到全球领先荷兰国际集团水平。 11月8日,Lmarena大型模型竞技场最新排名显示,Ernie-5.0-preview-1022所在的Wenx模型在文本任务分析,尤其是创意写作和复杂问题理解方面并列全球第二、国内第一。文信5.0在操作成绩上并不突出,但其多模态理解能力则更为突出。目前国外主要厂商中,Gemini对视频的理解速度较快。其他的,比如 OpenAi 的 GPT-4O,一次只能理解音频或视频。国内各大厂商也推出了多款视频理解模型,但尚未整合成统一的大模型。多模态理解能力将有助于整合更丰富的数据语料,帮助模型不断迭代,践行李彦宏“智能本身就是最大的应用,技术的变革速度是唯一的护城河”的发展思想。基米:基小米K2思维于11月6日正式发布,其在Last Examination(HLE)、自主网页浏览能力(Browsecomp)、复杂信息收集(SEAL-0)等多项基准测试中性能均达到SOTA水平,在代理代理、程序代理、写作和综合推理能力方面实现全面提升。具体来说,Kimi K2思维总共1TB参数,32B激活,采用INT4精度(更兼容推理硬件,对国产加速计算芯片更友好),支持256k上下文窗口,训练成本仅为460万美元(CNBC,杨志林在社交媒体上拒绝了它,称训练很难统计,大部分用于研究实验)。Kimi在Reddit上还透露了更多信息:1)受该模型的“长链推理机制”,思维推理效果好但响应慢。的效率后续会优化token。 2)当前K2思维模型的“人性张力”还不够,未来版本可以更加开放、真实地表达情感。 Kimi K2的思潮继Minimax-M2之后再次坐上开源模型的宝座,很大程度上体现了国产模型变异步伐的不断加快。 K2思维未来将进一步优化通证效率和情感表达,以证明工程工程的重要性。 Minimax:10月27日,Minimax正式开业,推出Minimax M2型号,专为代理商和码农打造。在pagpapalaya当时,它在Artificial Analysis (AA)的分析中获得了最高分。排名全球第五,开源第一。 M2模型在工具使用和深度搜索能力方面都非常接近海外最好的模型。从编程上来说,它比不上国外最好的车型,但在国内也属于顶尖水平。此外,M2 采用全注意力架构,但稀疏性进一步优化(总参数 230B,激活成本 10B),实现每百万输入代币 2.1 人民币(0.3 美元)的定价,每百万输出代币 8.4 人民币(1.2 美元)的定价,仅为 Claude 3.5 Sonnet 的 8%。虽然Minimax-M2只有230B参数和10B激活,但为充分注意使用它仍然实现低成本奠定了基础。它还将上下文窗口从上一代的100万个令牌减少到20万个,但它能够完成代理和代码的主要任务,甚至可以优化响应速度。总的来说,M2依然践行着现款车型相同的迭代方向——更好的性能和更低的成本。注意力机制、代理、泛化、数据等细节还有很大的打磨空间。 总结:海外GPT-5.1更新注重效率升级和个性化,国内模型也加速迭代。拜德u 文心5.0具有出色的多模态理解能力,有望为模型后续迭代提供更丰富的数据语料。 Minimax M2和Kimi K2的思想先后位居开源模型榜首。前者专为代理和代码而设计,成本仅为Claude 3.5 Sonnet的8%;后者将在代币效率、情感表达等工程模型方向不断迭代,优化模型性能。未来,依托国内的工程优势和庞大的用户群体的使用反馈,国产模型和AI应用产品具备追赶国外的基础。投资建议:国产模式加速突破,工程化成为AI落地的重要方向。
特别声明:以上内容(如有则包括照片或视频)由自媒体平台“网易”用户上传发布se账户”。本平台仅提供信息存储服务。
注:以上内容(包括照片和视频,如有)由网易HAO用户上传并发布,网易HAO是一个社交媒体平台,仅提供信息存储服务。

