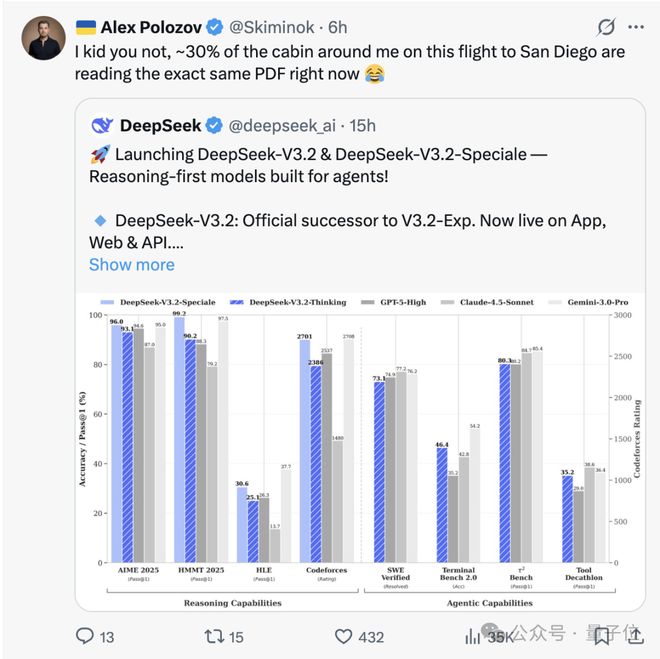
亨利 发表者:奥飞斯量子比特 |公众号Chatgpt三岁生日之际,硅谷热议的新模型来自Deepseek。准确来说,这是两个开源模型——Deepseek-V3.2Deepseek-V3.2-speciale。这两款车型到底有多强呢?有网友表示,在飞往圣地亚哥的航班上(疑似参加 Neurips 2025),有 30% 的乘客在盯着 Deepseek 的 PDF。上周,一条戏称 Deepseek 为“昙花一现”的推文在发布当晚就被浏览了 500 万次。除了普通网友之外,奥特曼也着急了:不仅启动了红色警报,还暂时推迟了在ChatGPT上公布的计划。与此同时,另一端的谷歌也未能幸免。网友直呼“灵魂呐喊”Google Gemini团队:别睡了,bDeepseek回来了。关闭精英资源是怎么回事?我们正在对抗闭源精英!总的来说,DeepSeek-V3.2模型已经达到了最高水平对当前开源模型在智能体评估中的应用进行了全面的评估,显着缩小了开源模型与领先的闭源模型之间的差距,宣告了落后于开源的闭源的结束。其中,标准版Deepseek-V3.2在识别测试中达到了GPT-5级别,略低于Gemini-3.0-Pro。 “特别版”Deepseek-V3.2-speciale不仅在各方面超越了GPT-5,而且在基本智能任务上也可以与Gemini-3.0-Pro竞争。此外,v3.2-special还获得了IMO、CMO、ICPC和IOI金牌,并在ICPC和IOI人类玩家中获得第二名和第十名。这不仅松解了开源模式落后闭源模式半年的质疑,也给硅谷的闭源AI公司带来了不小的压力。而且,现在还不是V4/R2。也就是说,还没等主菜上桌,硅谷就已经满是冷盘了。关于针对此时Deepseek-V3.2的结果,Deepseek研究院志斌在推特上给出了一个相对通俗易懂的答案:强化学习即使在长期背景下也可以继续扩展。为了理解这一说法,让我们回顾一下这篇论文。简单来说,Deepseek-V3.2实际上做了以下几件事:首先,它利用DSA Sparse pthen解决了长上下文效率问题,为后续的长序列强化学习奠定了计算基础。接下来,通过引入可扩展的RL,并将超过10%的预训练成本投入到后训练中,模型的整体推理能力和智能体的能力都得到了极大的提升。最后,为了探索推理能力的极限,Deepseek-v3.2-speciale 有意放宽了 RL 的长度限制,让模型生成极长的“思维链”,迫使模型通过深度自我修正和探索h 大量代币的产生。这意味着模型可以通过长链思维思考更多,通过自我探索i可以思考更长时间,从而解锁更强的推理能力。这样一来,模型就可以在不增加预训练规模的情况下,通过很长的思考(消耗更多的代币)过程实现性能的跳跃。实验结果仅证实了“超长路线下加固研究持续拓展”路线的正确性。正如苟志斌所说:如果说Gemini-3证明了预训练可以继续延伸,那么Deepseek-V3.2-speciale则证明了强化学习在长期背景下也可以继续延伸。我们花了一年的时间将 Deepseek-V3 推向极限。得到的教训是:训练后阶段的瓶颈不能通过等待“更好的基础模型”来解决,而是通过改进方法和数据本身来解决。换句话说,如果Gemini-3以“一堆k”赢得了上半场nowledge(预训练)”,随后Deepseek-v3.2-speciale以“Pile of Thinking(Long Context RL)”赢得了下半场。此外,对于大型模型达到天花板的说法,他表示:预训练可以缩放,RL可以缩放,上下文也可以缩放,所有测量仍然增加。这表明RL不仅有效,而且还可以通过缩放获得很大的好处(更大的批次,更长的时间)同时,有网友发现了为什么DeepSeek-V3.2在HLE和GPQA这样的知识基准测试中表现稍差!也就是说,Deepseek和领先模型的差距不再是技术问题,而是经济问题。我以为开源并不比闭源差! Deepseek-V3.2系列具有与领先的闭源模型相同的性能这时候就让大家看到“智能这么便宜,不用充电”。如果我们看输出 100 万代币的成本,Deepseek-V3.2 比 GPT-5 便宜约 24 倍,比 Gemini 3 Pro 便宜约 29 倍。随着输出代币数量的增加,这个空间最多可以扩大43倍。这是什么概念?就像如果让一个大模子一次性“写”一套《三体》三部曲,使用GPT-5大约需要800元,使用Gemini 3 Pro需要1000元左右。使用DeepSeekv3.2仅需35元左右!因此,性能相差无几,但价格却可以相差数十倍。我应该选择哪一边?答案就不用说了?对此,有网友表示,Deepseek-V3.2这种实惠的开源机型正在挑战gemiNi3.0 Pro。另一方面,Openai昂贵的订阅费立即令人不满意。当然,这并不意味着DeepSeekv3.2没有缺点。正如一位网友指出的可见,解决同样的问题,Gemini 只需要 20,000 个代币,而 Speciale 则需要 77,000 个代币。 (这其实就是上面提到的RL的权衡)不过,低廉的价格也在一定程度上弥补了现阶段speciale版本的弱点。总体来说,Deepseek还是比较实惠的。另外,对于硅谷来说可能比较困难的是,Deepseek-V3.2还可以直接部署在国产算力(华为、寒武纪)上,这将进一步降低模型实现的成本。此前,Deepseek-V3.2-Exp发布时,Deepseek在发布首日就对华为Ascend硬件和Cann软件栈进行了优化。虽然这次的Deepseek-V3.2系列没有明确说明,但很有可能会延续之前的策略。换句话说,不高兴的可能不仅仅是Google和Openai,还有他们的好兄弟Nvidia。不过这里的价格只是模型公司的定价,不是实际的价格实际的理解成本。虽然我们无法知道理解每个模型的实际成本,但从 Deepseek 的技术报告中可以看到一个明显的趋势:与上一代模型 Deepseek-V3.1-terminus 相比,Deepseek-V3.2 在最长上下文(128K)场景下成本降低了约 75% 至 83%。这意味着,随着注意力机制和后期训练的不断优化,底层推理的成本不断降低。正如一位网友总结的那样:Deepseek已经证明,实现强大的AI并不一定需要过多的资本投入。 [1]https://x.com/airesearch12/status/1995465802040983960[2]https://www.nbcnews.com/tech/innovation/silicon-valley-building-free-chinese-ai-rcna242430
特别声明:以上内容(如有则包括图片或视频)由guse自媒体平台“网易号”上传发布。本平台仅提供信息存储服务。
注:以上内容(我包括图像和视频(如有)由网易号用户上传并发布,网易号是一个社交媒体平台,仅提供信息存储服务。

